
I was just putting some finishing touches on this before I started to actually use and archive some of my stuff. To put it to an actual real world test.
Anyways, I tested an ADF generated ADF against an amiga transdisk ADF, and it failed. Turned out to be different by exactly one sector of all zeros in MY file versus the good file.
I tracked it down to a crappily written readtrack() routine where if I get a bad sector, but then at least one good sector after it, then the thing never retries. As a crappy patch, I check all sectors at the end of a track read and make sure there is good data in them. But this sucks. Even though I want and will have the same check in place, my read routine should be much much cleaner. I’m going to rewrite the routine.
Originally, I thought it was a data-size problem cropping up again, but I was wrong…..






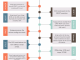



I completely restructured readtrack(). Basically re-did the loops, and the processing overall is just much better.
I basically check in several places whether or not to continue the decoding process. A single error brings further processing to a halt, and retries.
A transfer checksum error actually causes a full re-read of the disk, and this isn’t entirely necessary, but who cares. Generally speaking, when something goes wrong, I try to basically reset and then try again.
I get occasional soft errors on a disk from years ago, but the instant-retry method seems to really work.
It’s actually amazing to see my evil creation in motion. It handles errors automatically, retries, and verifies that everything is correct. This happens so fast, you are unlikely to know it’s happened, except when looking at the track times and status message errors generated.